ERAU Capstone Project for JPL
Summary
For my senior capstone at Embry-Riddle, our team collaborated with NASA's Jet Propulsion Laboratory (JPL) to evaluate the feasibility of deploying Generative AI on spacecraft. We developed an autonomous Large Language Model (LLM) system optimized for a Qualcomm Snapdragon SoC, focusing on offline image analysis and decision-making. This project pushed the boundaries of Edge AI, testing whether high-level reasoning can survive the extreme resource constraints of deep space.
Background
Deep space missions face a "data bottleneck": high-resolution sensors generate massive amounts of data, but communication bandwidth back to Earth is extremely limited. By moving AI processing to the "edge" (AKA directly onto the spacecraft), we can enable future opportunities like real-time data filtering, autonomous navigation, and astronaut support. Our mission was to build a rigorous testbench on a Snapdragon architecture to prove that these models can run reliably without any internet or cloud connectivity.
Details
- Hardware: Developed and profiled the model for the Snapdragon ARM CPU, with stretch goals for GPU/DSP acceleration.
- Models: Evaluated lightweight models like TinyLLaMA or DistilBERT to find the optimal balance between reasoning capability and power efficiency.
- Model Optimization: Implemented quantization (4-bit/8-bit) and pruning techniques to compress the model into a strict 6GB RAM footprint.
- Data Pipeline: Engineered a JSON-based I/O system to ensure the model's outputs were structured for autonomous integration with other spacecraft systems.
Architecture
Our system architecture is split into two components: static and dynamic. The static section covers the user and storage interfaces, while the dynamic section focuses on all subsystems and their interactions, covering the flow of execution during development, testing and runtime.
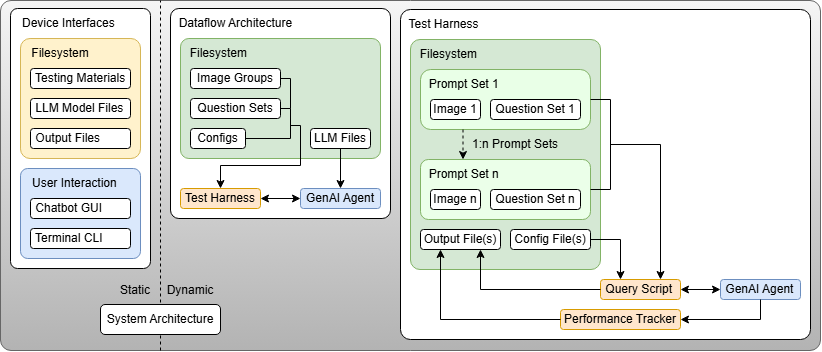
For our static architecture, our device interfaces are split into two categories: data and user. The data interfaces consist of the model material and output directories, stored on the local filesystem. The user interfaces consist of a terminal CLI and chatbot GUI, which allow users to interact with the model for sending queries, loading data, and viewing outputs. The core of our system is the GenAI agent, which processes given prompts and images to generate outputs.
For our dynamic architecture, the core autonomous portion of our system is the test harness. The test harness's role is to execute the GenAI agent against predefined prompt sets paired with test images. The test harness orchestrates query execution through a query script, monitors performance metrics via a performance tracker, and collects structured outputs and metrics for analysis. This architecture enables systematic evaluation of model accuracy, response time, and resource utilization, to assess the viability of LLM deployment in space.
Challenges
- Resource Constraints: Operating within a 6GB RAM ceiling required aggressive optimization that risked model "hallucinations" or lost accuracy.
- Reliability: Addressing the threat of Single Event Upsets (SEU) and Double Bit Errors (DBE) which can corrupt model weights in high-radiation environments.
- Zero Connectivity: Ensuring the entire stack—from pre-processing to inference—functioned in a 100% "air-gapped" environment.
Outcomes
- Functional Prototype: Our primary deliverable: To successfully deploy a quantized LLM on Snapdragon hardware, capable of offline image analysis and decision-making.
- Storage Constraints: To achive a total footprint (model, weights, and training/input data) of less than 64GB.
- Documentation: To deliver a comprehensive Preliminary Design Review (PDR), Test Report, and User Manual to JPL for future deployment and development.
- Validation: To prove our model and solution meets given spec through automated test cases and benchmarking for accuracy and response time.